打赏本站
微信
 支付宝
支付宝

支付宝
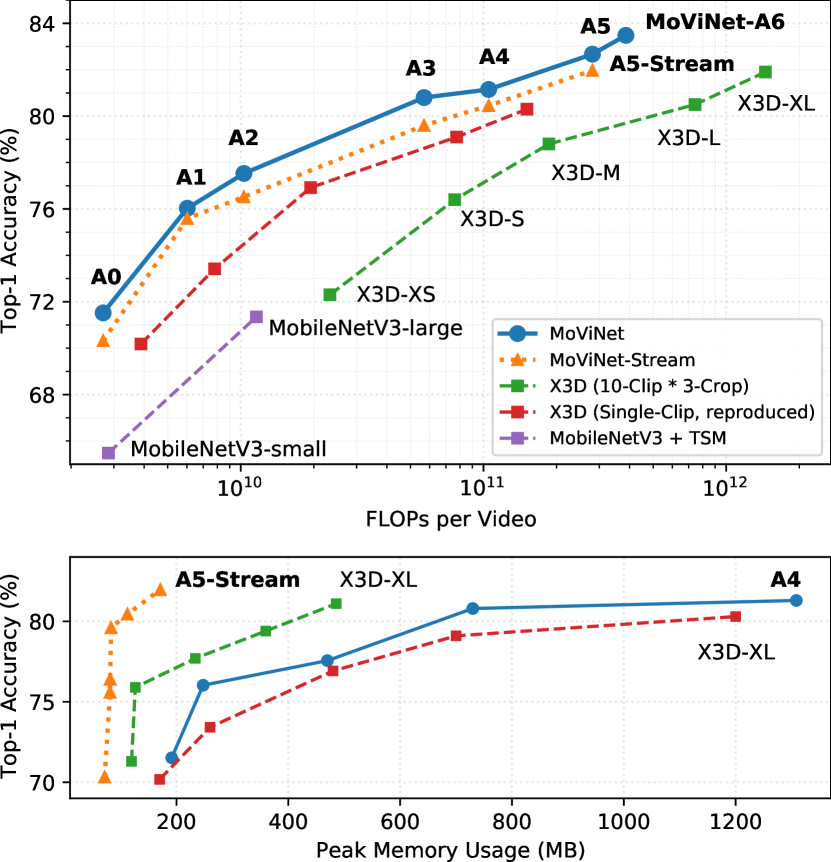
我们提出了移动视频网络 (MoViNets),这是一系列计算和内存高效的视频网络,可以在流视频上运行以进行在线推理。 3D 卷积神经网络(CNN)在视频识别方面非常准确,但需要大量的计算和内存预算,并且不支持在线推理,这使得它们很难在移动设备上工作。我们提出了一种三步方法来提高计算效率,同时大幅降低 3D CNN 的峰值内存使用量 ...
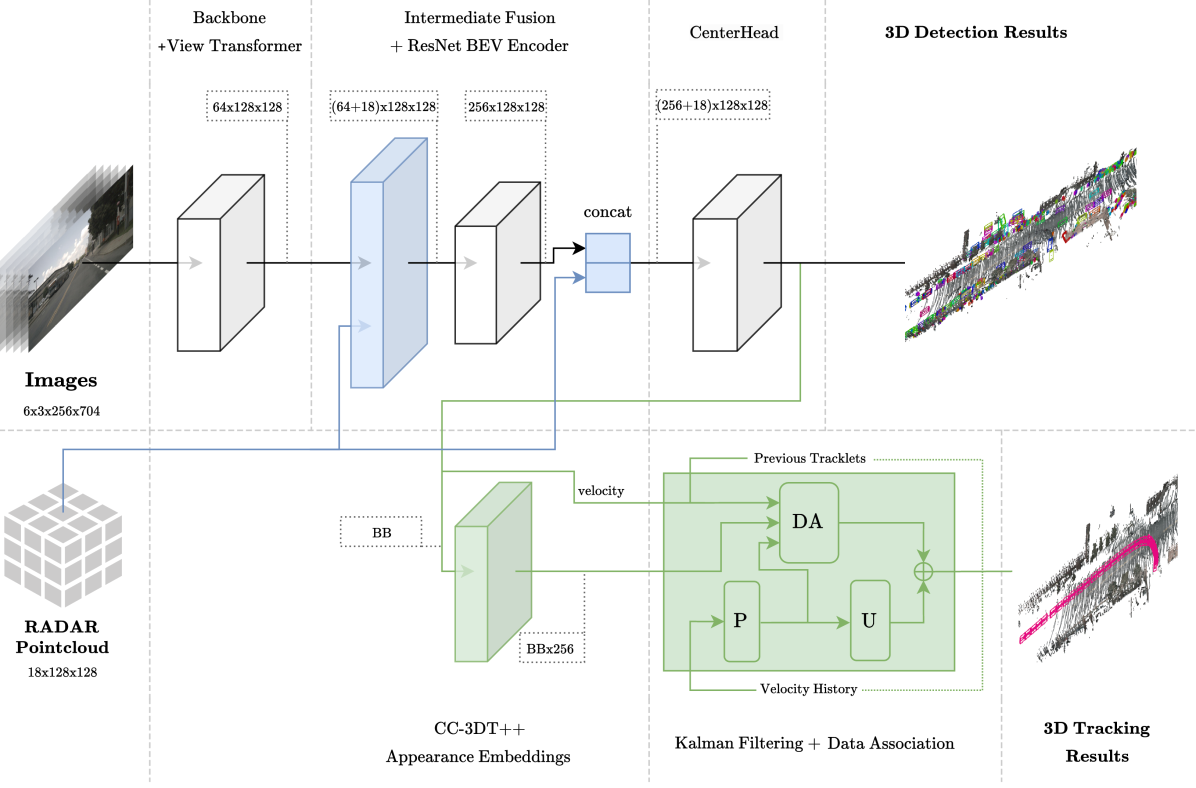
准确检测和跟踪周围物体对于实现自动驾驶车辆至关重要。虽然光探测和测距 (LiDAR) 传感器为高性能设定了基准,但仅摄像头解决方案的吸引力在于其成本效益。值得注意的是,尽管无线电探测和测距 (RADAR) 传感器在汽车系统中广泛使用,但由于数据稀疏和测量噪声,它们在 3D 探测和跟踪方面的潜力在很大程度上被忽视 ...
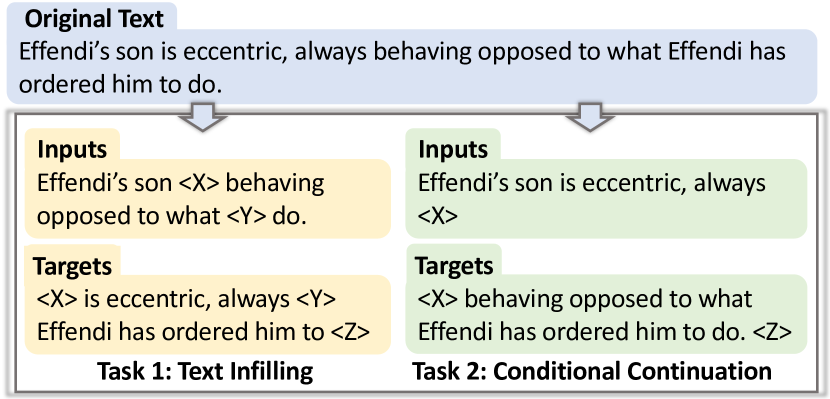
标准的多任务基准对于开发可以推广到各种下游任务的预训练模型至关重要。现有的自然语言处理(NLP)基准通常只关注理解或生成短文本。然而,长文本建模需要许多与短文本不同的能力,例如长距离话语和常识关系的建模,以及生成的连贯性和可控性 ...
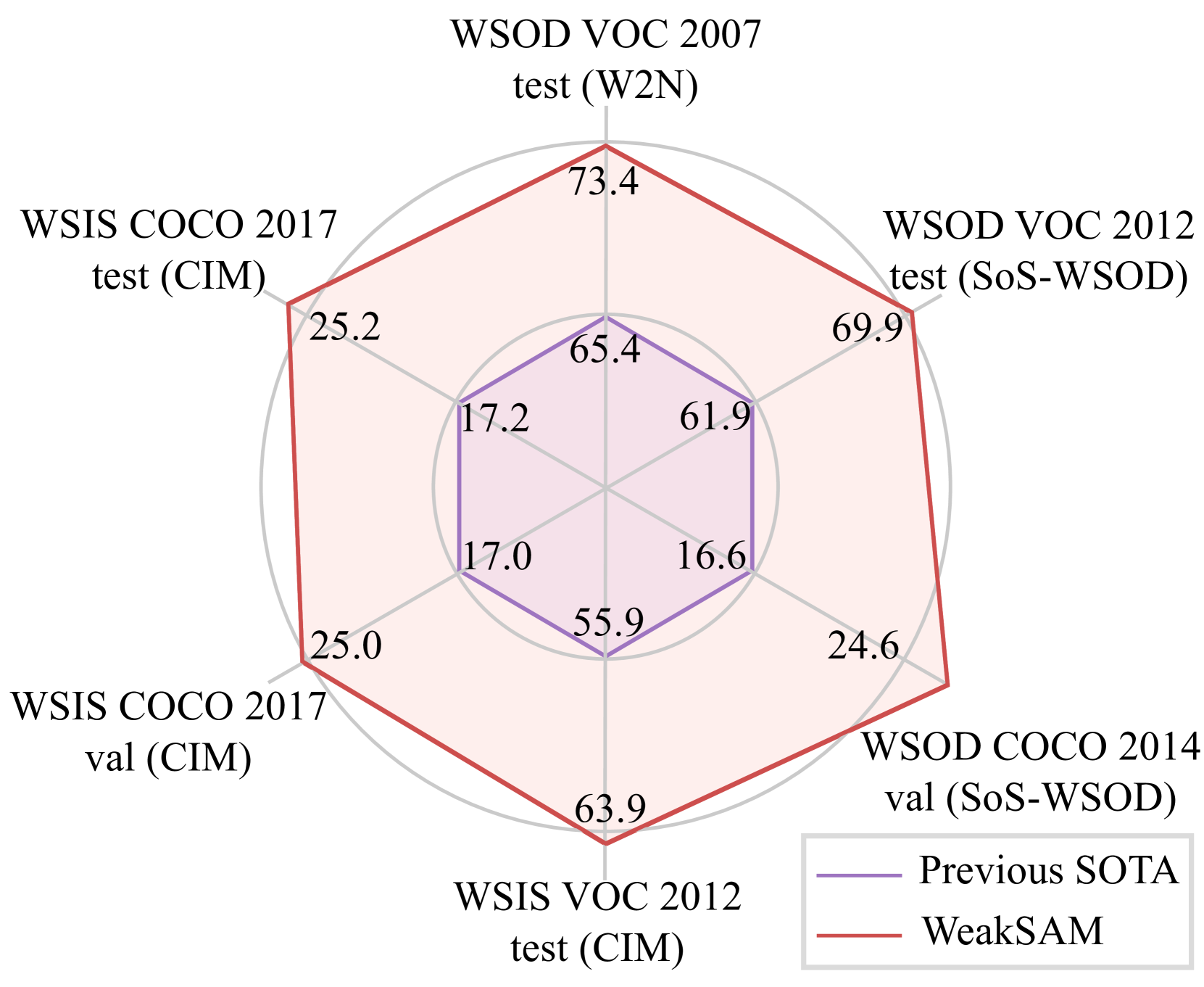
使用不精确监督的弱监督视觉识别是一个关键但具有挑战性的学习问题。它显着降低了人工标记成本,并且传统上依赖于多实例学习和伪标记。本文介绍了WeakSAM,并利用视觉基础模型中包含的预先学习的世界知识来解决弱监督目标检测(WSOD)和分割问题 ...
我们提出了一种新的视觉提示方法 Set-of-Mark (SoM),以释放大型多模态模型 (LMM)(例如 GPT-4V)的视觉基础能力。如图 1(右)所示,我们采用现成的交互式分割模型(例如 SEEM/SAM)将图像划分为不同粒度级别的区域,并用一组标记 e 覆盖这些区域 ...
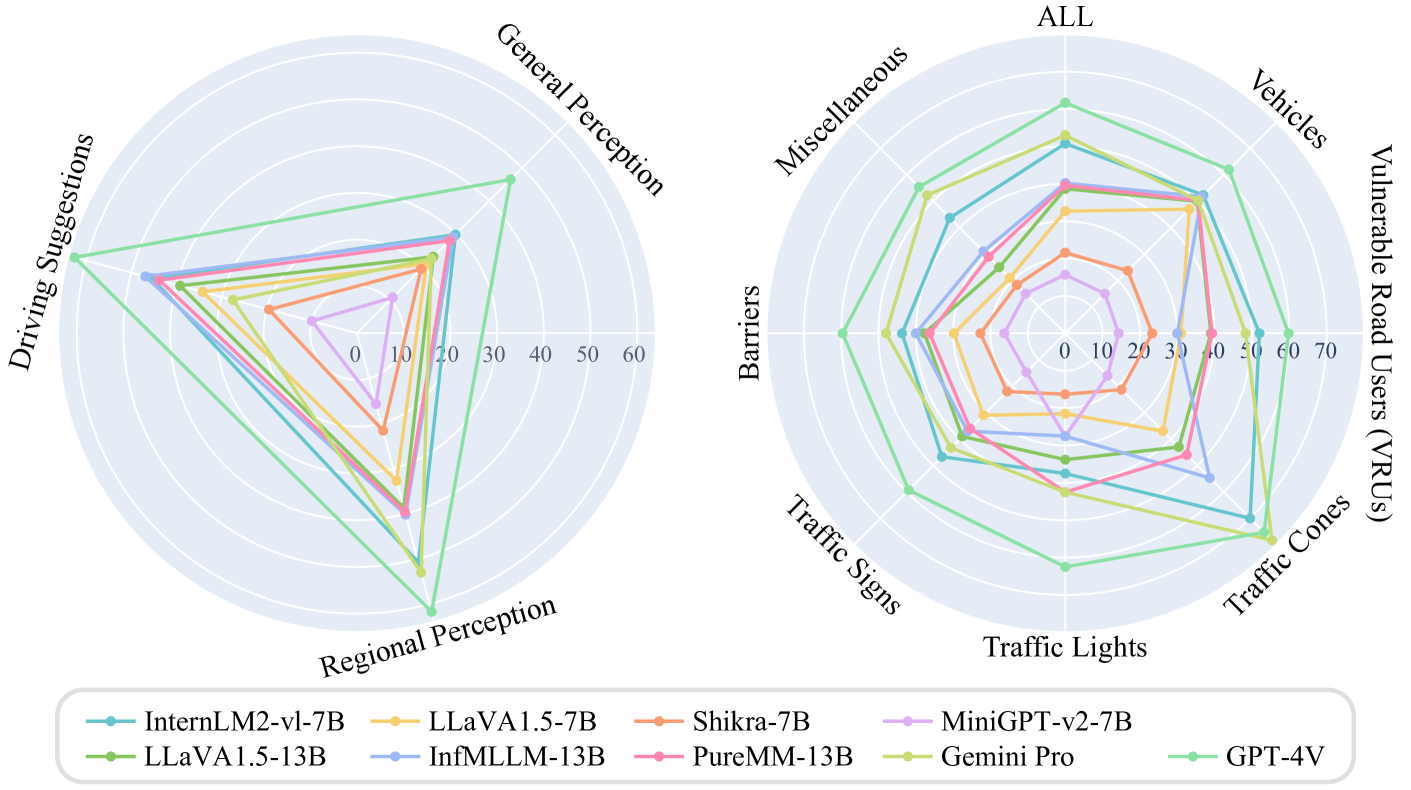
大视觉语言模型(LVLM)由于具有理解图像和视频的卓越视觉推理能力,在自动驾驶领域受到了广泛关注,极大地推动了可解释的端到端自动驾驶的发展。然而,目前对LVLM的评估主要集中在常见场景下的多方面能力,缺乏自动驾驶环境下的可量化和自动化评估,更不用说即使是最先进的自动驾驶感知系统也难以应对的严峻路况。处理。在本文中,我们提出了 CODA-LM,一种新颖的自动驾驶视觉语言基准,它为可解释的自动驾驶提供 ...
预测交通场景中的人体轨迹对于混合或完全自主系统中的安全至关重要。人类未来的轨迹由两大刺激驱动:社交互动和随机目标。因此,可靠的预测需要捕捉这两种刺激 ...

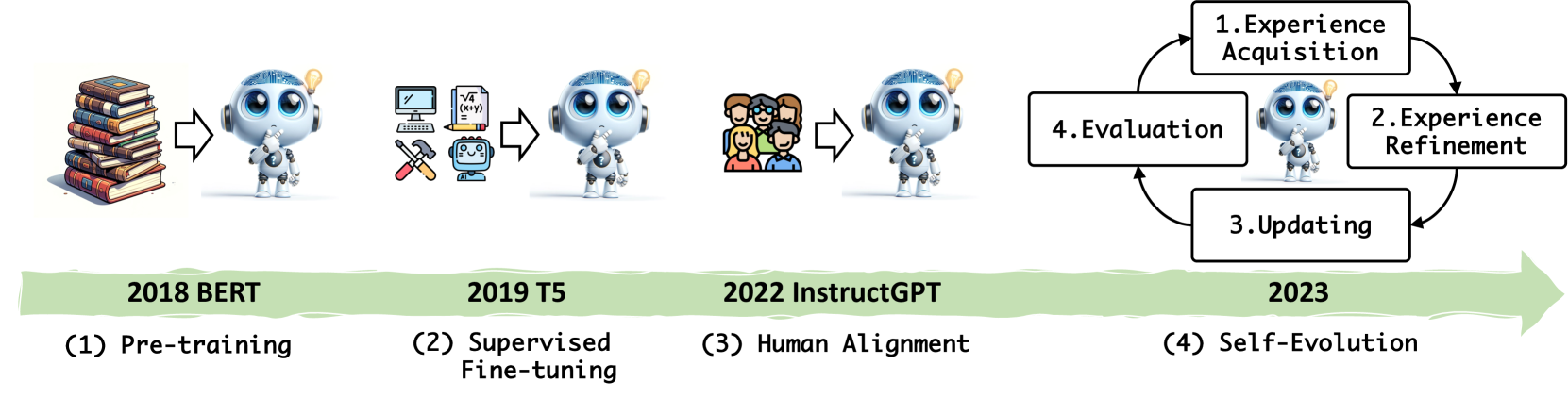
大型语言模型(LLM)在各个领域和智能代理应用中取得了显着的进步。然而,目前从人类或外部模型监督中学习的 LLM 成本高昂,并且随着任务复杂性和多样性的增加可能面临性能天花板。为了解决这个问题,使 LLM 能够自主获取、完善模型本身生成的经验并从中学习的自我进化方法正在迅速发展 ...